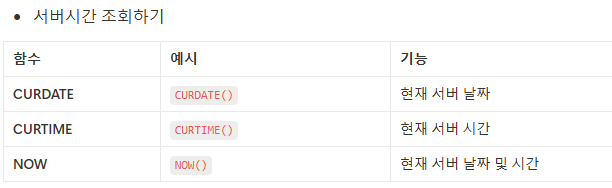
1. 날짜형 자료 기본My SQL 자료형한국은 UTC보다 9시간 빠르다. 방법1)#세션에서 시간대를 변경 SET time_zone = 'Asia/Seoul'; SELECT CURDATE(), CURRENT_TIME(), NOW(); 방법2) 글로벌 시간대를 변경한다. (ROOT 권한 필요)SET GLOBAL time_zone = 'Asia/Seoul'; SELECT CURDATE(), CURRENT_TIME(), NOW(); 방법3) 시간대를 변환하여 조회CONVERT_TZ(NOW(), FROMTZ, TO_TZ)SELECT CONVERT_TZ(NOW(), '+00:00', '+09:00') AS current_seoul_time; DATETIME vs TIMESTMAP 2. 날짜 변환 & 가공 함수YEA..