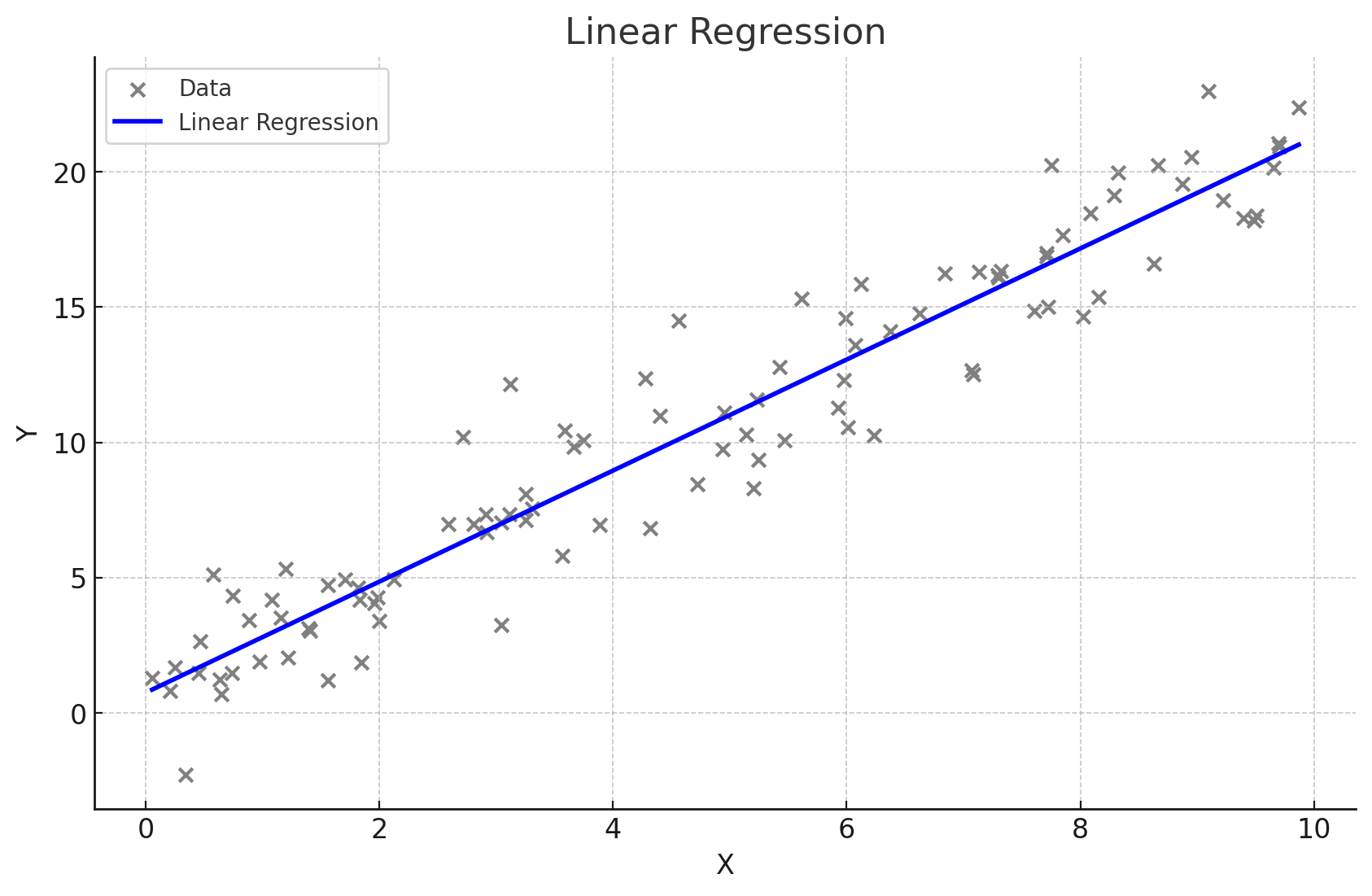
1. 단순선형회귀단순선형회귀란 ?하나의 독립 변수(X)와 하나의 종속 변수(Y) 간의 관계를 직선으로 모델링하는 방법회귀식Y = β0 + β1X, 여기서 β0는 절편, β1는 기울기특징독립 변수의 변화에 따라 종속 변수가 어떻게 변화하는지 설명하고 예측한다.데이터가 직선적 경향을 따를 때 사용함.간단하고 해석이 용이하다.데이터가 선형적이지 않을 경우 적합하지 않다.단순선형회귀는 어떨 때 사용하는가 ?- 하나의 독립변수와 종속변수와의 관계를 분석 및 예측할 때광고비(X)와 매출(Y) 간의 관계를 분석할 때현재의 광고비를 바탕으로 예상되는 매출을 예측 가능import numpy as np import pandas as pd import matplotlib.pyplot as pltfrom sklearn.lin..