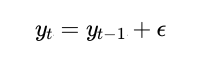3. 확률 보행 프로세스 3.1 확률 보행(Random Walk)란? 평균과 분산이 시간이 지나도 일정하지 않은 비정상 시계열 시간이 지남에 따라 무작위로 이동하는 경로를 설명하는 수학적 모델 확률이 개입하는 다양한 현상을 설명하는 데 필수적인 모델, 자연과학, 경제학, 컴퓨터 공학 등에 응용yt : 현재 값yt-1 : 이전 시간 단계의 값C : 상수, 기본적으로 시계열이 가지는 평균 값εt : 백색 소음, 표준정규분포를 따르는 난수로 시계열에 포함된 무작위적 요소(노이즈)이 공식에서 현재 값이 과거 값, 상수, 백색소음의 입력 값으로 결정된 함수라는 점을 기억-> 현재 값이 과거 정보와 랜덤한 변동의 영향을 받는다는 의미! 3.1 정상성이란 ?시계열의 통계적 성질이 시간에 따라 변하지 ..