프로젝트 진행 중 [마감 지연 건수] 컬럼 전처리 과정
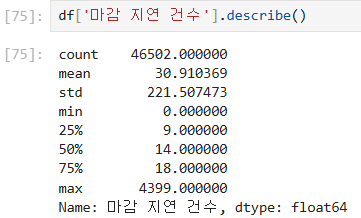
df['마감 지연 건수'].describe()

min 값이 -3으로 건수가 음수인 건 말이 안됨. > 이상치라고 판단
은행에 대한 도메인 지식이 부족하므로 다른 행들을 본 결과 음수로 잘못 입력됐다고 판단.
def remove_minus(series):
if series < 0:
return (-series)
else: return (series)
df['마감 지연 건수'] = df['마감 지연 건수'].apply(remove_minus)
min 값이 0으로 바뀐 것을 확인 할 수 있다.
마감 지연 건수가 4399로 이상치라고 판단하였다.
IQR을 통해 이상치 값을 제거하기로 하였다.
q1=df['마감 지연 건수'].quantile(0.25)
q2=df['마감 지연 건수'].quantile(0.5)
q3=df['마감 지연 건수'].quantile(0.75)
iqr=q3-q1
condition=df['마감 지연 건수']>q3+1.5*iqr
df[condition]
각각 25% 50% 75%의 값을 q1, q2, q3에 넣어주었고,
df에 condition을 적용한 값만 출력해보았다.

해당하는 값만 출력된 모습
a = df[condition].index
a
해당하는 인덱스 값들이 출력되는 것을 확인함.
여기서 행을 삭제하려면
df.drop(a,inplace=True)
행의 값을 바꿔주려면
df[df['마감 지연 건수'] > 31.5] = np.nan
df.groupby('고객번호')['마감 지연 건수'].apply(lambda x: x.fillna(x.mean()))
q3+1.5*iqr = 31.5이다. 조건을 걸어 이상치들을 null값으로 바꿔주었다.
null 값들을 [고객번호]로 그룹화하여 각 그룹 당 [마감 지연 건수]의 평균값으로 채워주었다.
## 할당을 해주지 않아서 오류가 발생하였다.
df['마감 지연 건수'] = df.groupby('고객번호')['마감 지연 건수'].transform(lambda x: x.fillna(x.mean()))
추가로 groupby를 사용했을 때, 행이 줄어들게 되는데 그대로 [마감 지연 건수] 컬럼에 할당해주니 인덱스 오류가 발생하였다.
apply 대신 transform으로 바꾸었을 때, 행을 삭제하지 않아 문제 없이 실행되었다.

^ㅁ^